9. Unload to data lake
Playing the role of the marketing user.
We will find product popularity by the customer’s state on a 30/90 day rolling average
select
A.product_category,A.product_parent,
A.review_date as Review_Date,
C.ca_state as Customer_State,
AVG(CAST(A.star_rating as decimal(3,2))) over (partition by product_parent order by A.review_date, A.star_rating rows 30 preceding) as review_rating_30rolling_avg,
AVG(CAST(A.star_rating as decimal(3,2))) over (partition by product_parent order by A.review_date, A.star_rating rows 90 preceding) as review_rating_90rolling_avg
from
public.product_reviews A,
public.customer B,
public.customer_address C
where A.customer_id = B.c_customer_sk
and B.c_current_addr_sk = C.ca_address_sk
and marketplace = 'US'
and A.review_date > '2015-01-01'
order by A.product_parent, A.review_date
limit 1000;
You will see the following output
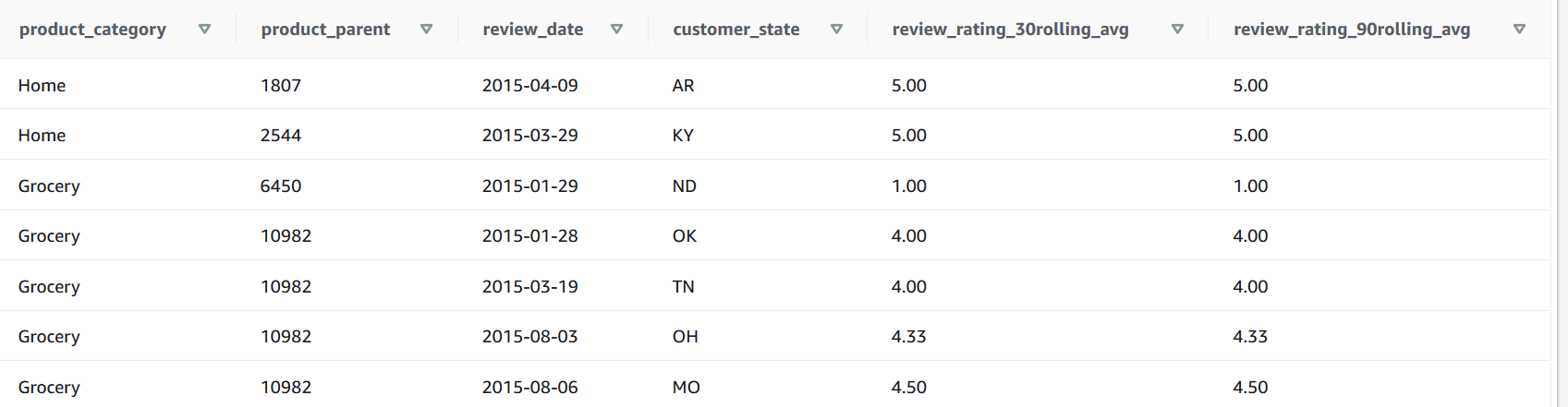
The result are very useful! Now let’s export the result back to data lake to share it with other teams. We will use unload command to export to data lake in parquet format using partition column.
Please replace the <TaskDataBucketName> and <RedshiftClusterRoleArn> in the following query before execution
unload ('select
A.product_category,A.product_parent,
A.review_date as Review_Date,
C.ca_state as Customer_State,
AVG(CAST(A.star_rating as decimal(3,2))) over (partition by product_parent order by A.review_date, A.star_rating rows 30 preceding) as review_rating_30rolling_avg,
AVG(CAST(A.star_rating as decimal(3,2))) over (partition by product_parent order by A.review_date, A.star_rating rows 90 preceding) as review_rating_90rolling_avg
from
public.product_reviews A,
public.customer B,
public.customer_address C
where A.customer_id = B.c_customer_sk
and B.c_current_addr_sk = C.ca_address_sk
order by A.product_parent, A.review_date')
to 's3://<TaskDataBucketName>/rll-datalake/reports/'
iam_role '<RedshiftClusterRoleArn>'
FORMAT PARQUET
ALLOWOVERWRITE
PARTITION BY (customer_state)
;
Once unload command is completed, You can navigate to Amazon S3 using the following url.
Please replace the <TaskDataBucketName> in the following url
https://s3.console.aws.amazon.com/s3/buckets/<TaskDataBucketName>/rll-datalake/reports/?region=us-east-1&tab=overview
You will see customer_state is used as the partition key
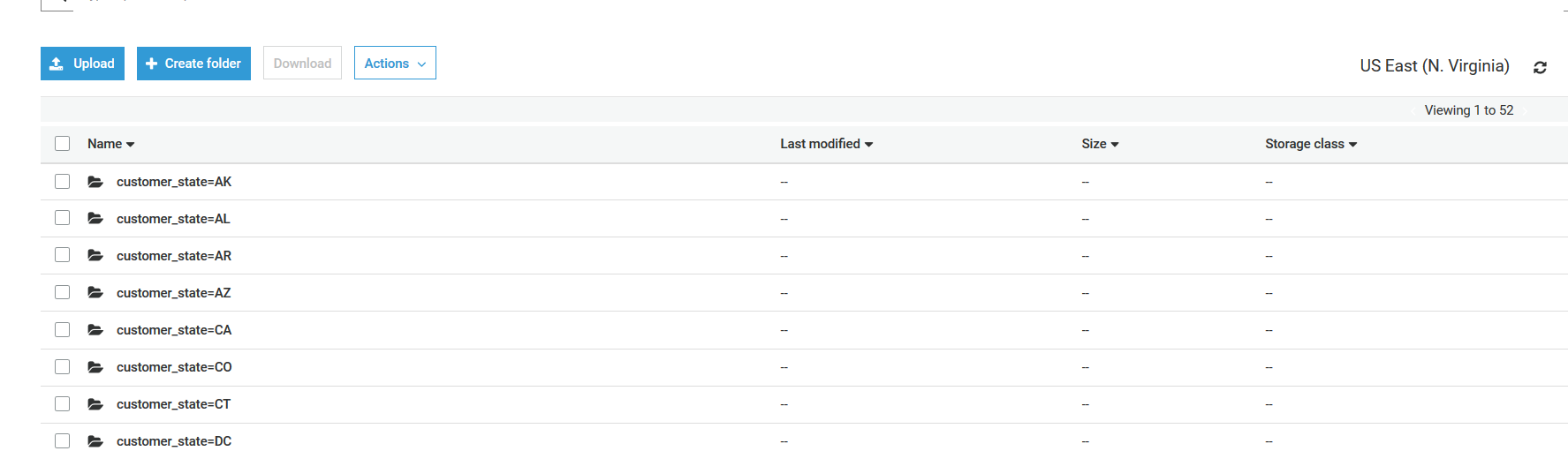
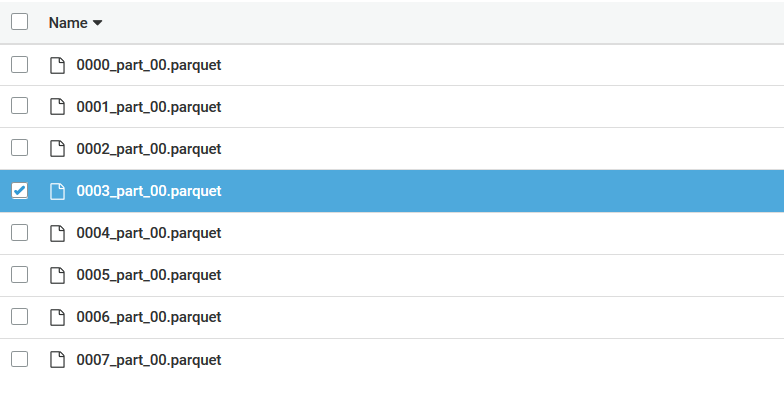
Click on folder customer_state=CT, you will see the parquet files
When more and more marketing users are going to execute the same query with different filters, you can convert the query into a materialized view to improve performance of repeated queries. You compute the materialized view once and query number of times. Reference: https://aws.amazon.com/blogs/big-data/speed-up-your-elt-and-bi-queries-with-amazon-redshift-materialized-views/
Let’s convert the complex query into a materialized view. Materialized views can have different distribution and sortkeys than the underlining tables.
create materialized view mv_product_review_analysis
sortkey(Customer_State, review_date)
as
select
A.product_category,A.product_parent,
A.review_date as Review_Date,
C.ca_state as Customer_State,
AVG(CAST(A.star_rating as decimal(3,2))) over (partition by product_parent order by A.review_date, A.star_rating rows 30 preceding) as review_rating_30rolling_avg,
AVG(CAST(A.star_rating as decimal(3,2))) over (partition by product_parent order by A.review_date, A.star_rating rows 90 preceding) as review_rating_90rolling_avg
from
public.product_reviews A,
public.customer B,
public.customer_address C
where A.customer_id = B.c_customer_sk
and B.c_current_addr_sk = C.ca_address_sk
and marketplace = 'US'
and A.review_date > '2015-01-01';
Run the following query using the materialized view
select * from mv_product_review_analysis
where customer_State = 'VA'
order by product_parent, review_date limit 1000;